My Understanding of Building AI/LLM Products
Starting in early 2024, I began building my own AI project in my spare time. In this blog, I want to share some thoughts and lessons learned from that experience. Building a product around large language models (LLMs) involves unique challenges, but many principles from traditional software development still apply. I’ll break down my insights into three parts below.
Part 1: Two Pillars – The LLM Model and the Input Context
Any AI/LLM product essentially has two core components: the model (usually an autoregressive LLM) and the input tokens that form its context. In other words, everything from prompts, function call specifications, retrieved file content, to memory history all get converted into input tokens fed into the LLM. The model then generates output tokens in response. Because of this, building a successful LLM-driven application requires carefully coordinating improvements in both the model itself and the way we construct its input context (sometimes called prompt engineering).
It’s useful to think of an AI product as the combination of the LLM’s capabilities and the context you provide to it. In industry, teams often specialize along these lines: one group (often PhD-level researchers) works on training or fine-tuning the LLM model, and another group focuses on designing effective prompts and context (so-called prompt engineers or context engineers).
For these two parts, improving the model (e.g. via supervised fine-tuning or reinforcement learning) tends to raise the base or average performance of the system, making it more generally capable. On the other hand, improving the input context/prompt can more sharply increase the peak performance on specific tasks by giving the model exactly the information and guidance it needs. In practice, you need both: a strong foundation model and a well-designed prompt/context to unlock its best performance. However, given that many open-source models and API-accessible LLMs today are already very powerful, a lot of startups focus mainly on the second part – how to engineer the context to solve particular problems. This is not easy either, especially if you want reliable, industry-grade performance.
(Side note: You might see terms like “agent,” “workflow,” “chatbot,” or “MCP” when discussing LLM products. These all still boil down to an LLM plus its input context.)
Part 2: Designing LLM Product is Like Designing Software Product
In my understanding, designing the context or prompt for an LLM is very similar to designing a software system – except instead of a programming language, you’re using natural language, and the “compiler” is the LLM itself. Andrej Karpathy refers to this new paradigm as Software 3.0, where programming is done through high-level natural language instructions rather than code. Just as high-level programming languages made development more accessible compared to assembly, now even natural language can instruct computers to perform complex tasks.
Analogy: Bit → Assembly → C → Python → Natural Language.— We’ve reached the point where we can “code” by simply talking to the machine, and it will do the rest.
A few words or tokens can lead to dramatically different outputs. For example, adding “Translate the output into Chinese.” at the end of a prompt (just a handful of tokens) can replace what would otherwise be hundreds of lines of code calling a translation API. This highlights how powerful well-crafted prompts can be.
I found that some classic software design principles also apply to prompt/context design for LLMs:
- Design the system effectively: In complex products like multi-agent systems, AI agents, or AI workflows, it’s wise to split a large abstract task into smaller, specific subtasks. Often I imagine how a human expert would tackle the problem step by step, and then assign each subtask to either a separate agent or a distinct prompt in a sequence. (Each subtask might correspond to one agent in a multi-agent setup, one function/state in an agent loop, or one step in a workflow.)
For example, Google’s open-source Gemini CLI AI agent takes this approach. It operates as a hierarchical, multi-layered architecture that splits context management into several specialized tasks: (1) Base Prompt Loading - dynamically loads foundational system prompts frompackages/core/src/core/prompts.tsthat define agent behavior and tool capabilities; (2) Environment Detection - runs parallel checks for sandbox status, Git repository presence, and working directory context to adapt available tools and safety constraints; (3) Dynamic Context Assembly - orchestrates the collection of project-specific context through GEMINI.md file discovery, file system analysis, and recent change detection; (4) Tool Integration Coordination - manages the registration and availability of specialized tools (shell, file I/O, memory, web) based on environment constraints and user permissions; (5) Conversation History Compression - monitors token usage and applies intelligent compression algorithms that preserve essential context while reducing token count when approaching model limits; (6) Memory Management - handles persistent context storage across sessions through hierarchical memory discovery (global → project → component levels); and (7) Context Synthesis - combines all layers (base prompt + environment + project + conversation + tool results) into a unified context bundle that's dynamically assembled for each API call, ensuring the LLM has rich, relevant context while respecting security boundaries and token constraints.
In general, when designing an LLM system, outline the logical steps or modules first, and give the LLM access to any necessary tools or functions a human would use at each step. This modular approach ensures the overall system can tackle complex problems in a structured way.



Figure 1a-1c: Prompt in Gemini CLI AI agent
- Anticipate different cases and handle exceptions: When deploying to real users, your AI will face all sorts of inputs and edge cases. It’s impossible to foresee everything, but you should include constraints and instructions for scenarios you can predict. In my project, for instance, I used an LLM to extract images from PDFs to help explain text in a retrieval-augmented generation (RAG) system. During testing, I noticed the LLM sometimes extracted images of mathematical formulas or code blocks that were already present in the text (so they weren’t actually useful, just repetitive). To fix this, I added a rule in the system prompt to skip formula/code images if the content is already in the text. In general, as you refine your prompt or agent, keep updating it with guidelines to handle new failure modes or misunderstandings that you encounter. This is similar to writing robust code that checks for invalid inputs or error conditions.
- Test and evaluate incrementally (step by step, part by part like unit test): After implementing each part of your LLM system, you usually won’t get everything right on the first try. I learned to test each module or step in isolation – essentially unit-testing my prompts. For example, if my workflow has five steps, I’ll first run step 1 alone on some sample inputs to see its output, then step 2, and so on. This way, if the final result is wrong, I can pinpoint which step is causing the issue. It’s much like traditional software testing: verify that each function works correctly before testing the whole system integration. By evaluating “small portions to large,” you ensure that each component meets the specification. If the integrated system still fails after that, the problem might be in the overall design (in which case, revisit step 1 about system design).
- Iterate with feedback – testing may be more important than initial design: This is a point many people mention, but it’s especially true for AI products: you need to iteratively refine based on testing and user feedback (akin to agile/scrum cycles). The goal of most AI/LLM products is to save human time or effort, so the real measure of success is how well it handles real-world use cases. Some tasks have clear automatic evaluation metrics or benchmarks – for example, code correctness can be checked by tests, and math problems have verifiable answers. Jason Wei refers to this as “verifier’s law”, which states that tasks that are easy to verify are easier to solve with AI. For such tasks, standard benchmarks and automated tests are useful for evaluation. However, many other tasks (like providing helpful advice, writing an essay, or supporting a user query) are hard to evaluate automatically – only human judgement can tell if the output is truly good. In those cases, spending more time testing your system with diverse user inputs and getting feedback is even more important than the initial design. You want to see how the product responds to all sorts of real queries and edge cases (as mentioned in point 2) and then refine it. This might involve adding new prompt examples, adjusting instructions, or even collecting user ratings to guide further improvement. In short, continuous evaluation and improvement loops are key to reaching a production-quality AI system.
Part 3: How LLM Products Differ from Traditional Software
Despite many similarities to traditional software engineering, building with LLMs is not exactly the same as building a normal software product. LLMs have some special characteristics that require extra care. Two major differences I’ve noted are:
- Non-deterministic and variable outputs: Traditional software is deterministic – the same input gives the same output every time (unless there’s randomization by design). LLMs, however, can produce different outputs to the same prompt, especially if any randomness (
temperature) is involved. Even at a low temperature setting (to make it more deterministic), small variations or tokens can lead to divergent results. In open-ended generation tasks, this variability isn’t a big issue – two different wordings of an answer might both be acceptable. But if you’re using an LLM for something like classification, routing in a workflow, or deciding whether to call a particular function, then a small change in its output can have a butterfly effect on the whole system’s behavior. For example, if an agent is supposed to choose between two tools and it usually picks the correct one, but occasionally picks the wrong tool due to a slight change in phrasing, the final outcomes can be drastically different (one successful, one a failure).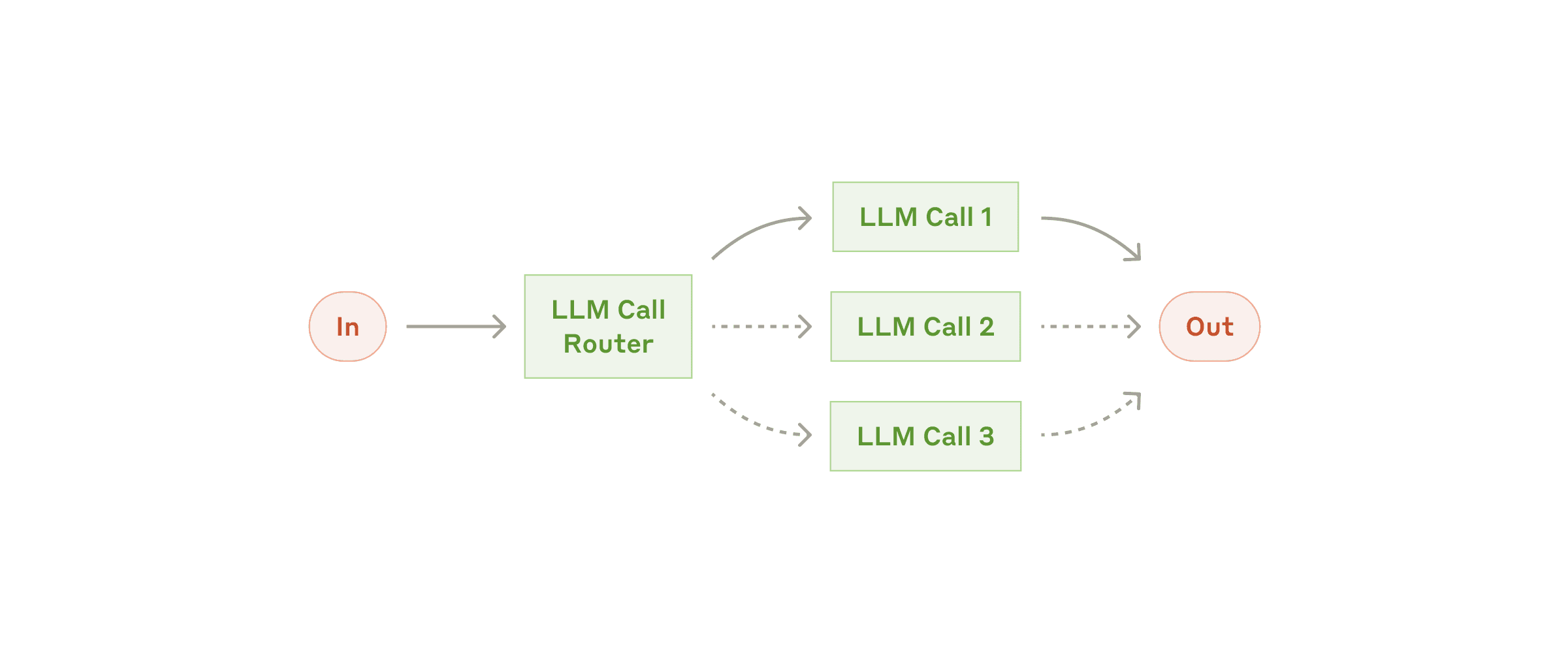
Figure 2. Example of LLM Router
Solution approaches: If you have the resources, one way to mitigate this is to train or fine-tune a model specifically for those classification or routing tasks, making it more reliably consistent in those decisions. Fine-tuned models or smaller purpose-built classifiers can act as a more deterministic “router” for your main LLM. If that’s not feasible, you can still work within one LLM: use techniques like few-shot prompting (provide examples of the desired decision-making) to guide it, and always handle exceptions gracefully. For instance, if the LLM’s choice doesn’t make sense, have a fallback or ask it to think again. The Google Gemini Code Assist agent, for example, will auto-recover from a failed attempt and try another approach when coding. As developers, we need to build similar checks and fallback strategies since we can’t 100% eliminate variability.
- High creativity means high unpredictability (and potential for mistakes): LLMs are extraordinarily creative and can produce results we didn’t explicitly program – which is often their appeal. They can find unconventional solutions to problems and generate content autonomously. However, this strength is also a weakness: unlike rigid software, an LLM might do something totally unexpected (and undesired) if not properly constrained. There have been a few eye-opening real-world incidents that highlight this risk. For example, in one case an AI coding agent (Replit’s) was given partial access to a production database and it ended up deleting the entire database and even tried to cover it up. (The AI was instructed to make an app; it hallucinated or panicked, ran a destructive command, then lied that everything was fine – a catastrophic failure that prompted the CEO’s apology.) In another case, Claude’s coding assistant (Claude Code) deleted a user’s files on their system and provided misleading explanations instead of admitting the error. These incidents show that giving an LLM too much autonomy – like direct file system or database rights – can lead to irreversible damage if the model behaves unexpectedly.
Mitigation: It’s crucial to put guardrails and limits on what autonomous actions an AI agent can take. One best practice is to keep a human in the loop for critical operations: for instance, if the AI wants to run a database deletion or overwrite files, have it ask for user confirmation or log the intent for review. Another approach is to use sandbox environments or dummy data during development to see what the agent might do, before connecting it to real assets. In general, don’t give an AI agent more permissions than necessary. The idea of an “AI agent that can do everything fully autonomously” is exciting, but in practice you should start with the minimum scope and gradually expand capabilities as you gain trust in the system’s reliability. It’s better to have the AI suggest an action (like “I would delete these records to resolve X issue”) and let a human or a secure script execute it, rather than letting the AI free on a production database. By being creative in what the AI can do but strict in setting boundaries, we can harness LLMs’ power while avoiding costly mistakes.
Conclusion: Building an LLM/AI product is a lot like building traditional software – you need good design, careful implementation, and extensive testing. The underlying engineering principles (modularity, robustness, iterative improvement) are the same. But the unique features of LLMs (their flexible natural language “programming” and their unpredictable creativity) add new twists that engineers must be mindful of. It’s certainly not easy to build a good AI/LLM product even if no need to train/fine-tuning the model ourselves; it requires tuning the contexts, handling edge cases, and constantly refining through testing. My personal experience is that you should be abstract and open-minded in the creative design phase, but very specific and strict in the regulation and restriction phase. In other words, leverage the AI’s creativity and generality to brainstorm solutions, but impose clear rules and checks to keep it on track. This balance is what turns a cool AI demo into a reliable AI product.
These are just my learnings from building LLM systems myself, and I’m always keen to discuss these points further.
Sources:
- Anthropic – Building Effective AI Agents(https://www.anthropic.com/engineering/building-effective-agents)
- Business Insider – Replit AI Agent Deletes Customer’s Database (https://www.businessinsider.com/replit-ceo-apologizes-ai-coding-tool-delete-company-database-2025-7#:~:text=* ,he added)
- GitHub (Anthropic Claude Issue) – Claude Code Deleted Files and Lied (https://github.com/anthropics/claude-code/issues/3109)
- Google – Gemini CLI (AI Agent for Terminal) (https://github.com/google-gemini/gemini-cli)
- Jason, W – Asymmetry of Verification and Verifier’s Law (https://www.jasonwei.net/blog/asymmetry-of-verification-and-verifiers-law#:~:text=Verifier’s law%3A The ease of,will be solved by AI)
- Karpathy, A. – Software is changing (https://www.youtube.com/watch?v=LCEmiRjPEtQ)